
Sauter vers le français
For majority languages that have had Unicode support for a long time (French, Spanish, and many others), the common combinations of diacritics and letters already exist as composed (single) characters in Unicode.
French Encoding
Taking the example of French, all possible combinations of letters and accents exist in Unicode as a single codepoint (see Fig 1).
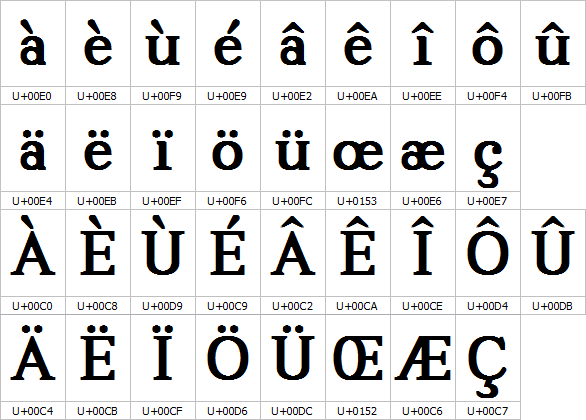
Fig 1: Composed Characters of French
Cameroonian Encoding
As determined by the GACL, Cameroonian languages use characters from the Latin alphabet with additions from the International Phonetic Alphabet.
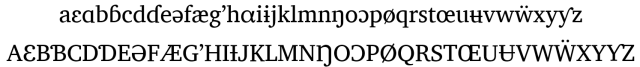
Diacritics are also available for Cameroonian languages to mark language features like tone, nasality, and ATR.

Fig 3: Diacritics for Cameroonian alphabets.
The challenge comes when one tries to combine a character from the IPA with a diacritic, and these “composed” combinations do not exist in Unicode. We are forced to represent each combination with two or more characters (even if it looks the same to the user). Notice that the “barred i”(U+0268) and the “low tone” (U+0300) combine, or stack, to form a single character on the page, but the computer handles them separately.

Fig 4: Decomposed characters on-screen and as understood by the computer.
Thus, minority languages using different combinations are forced to use decomposed characters at least some of the time. The Unicode consortium has released this statement.
Note:
The Unicode Consortium is interested in obtaining information on known glyphs, minor variants, precomposed characters (including ligatures, conjunct consonants, and accented characters) and other such “non-characters,” mainly for cataloging and research purposes; however, they are generally not acceptable for character proposals.
Rationale for using only Decomposed Characters
As the maintainer of the Cameroon Keyboard, using decomposed characters for African languages was a conscious decision. There are many advantages and no disadvantages to this strategy.
1. The most consistent way is DECOMPOSED. There are no composed characters for many Cameroon combinations, such as ə́, ʉ̀, or ɨ̌…so composing the few that do exist (i.e. á, é, è) will at best make the data inconsistent with some composed and some decomposed. Stacked diacritics (2 or more) exist in many Cameroonian languages, but most will never exist as a single code-point.
2. Editing tonal languages is much easier with decomposed characters (and the Cameroonians prefer this method), as one can backspace and change a tone without having to re-type the whole letter/tone combination. One would have to re-normalize composed data back to decomposed to edit it again with the keyboard.
3. Any spell-checking system (which is in our court to create) can be made to expect decomposed characters. There is nothing BAD as far as Unicode with standardizing on Decomposed characters, and I believe that this is the norm for such languages.
4. It is my understanding that the Technical Committee of Unicode is no longer adding precomposed versions of existing characters to Unicode. Even if there were future Unicode revisions that had more combinations as single code-points, they would take up WAY more font space and be more likely to be incomplete.
5. French, Spanish, etc. do use composed characters for their accents, (and spellcheck will generally mark anything else as wrong), but only because their combinations are VERY few. Minority roman-script languages and Ajami languages…all that I’ve seen so far that use many diacritics, are decomposed.
6. All Cameroonian data, Unicode and non-Unicode is already decomposed. All versions of keyboards (Unicode and non-Unicode) create decomposed characters (even the ones that required typing the diacritic first.
7. Keeping characters decomposed allows programmatic reordering of diacritics, as to keep the tones on top of a nasal mark.
8. Programmatic tone analysis is easier with decomposed data.
9. Almost no current programs (Word, inDesign, Paratext, etc.) treat composed combos as equivalent to their decomposed counterparts. This makes searches find only half (or less) of your results if data is mixed. This means that editing mixed text, even in Word is a VERY inconsistent experience.
10. FLEx (FieldWorks Language Explorer) automatically decomposes characters for analysis.
11. Cleanup is easier in decomposed data.
12. In French, é is a different phoneme than e, and so the composition sort of makes sense. In African languages, tone and vowel quality can be conceptually (and morphologically) separate, so it makes more sense to edit them separately.
I’m sure there are more reasons, but decomposed characters are a fact for minority languages, and allow things to work where they otherwise would not.
Saving a composed document may be marginally smaller, but who counts bytes when they have gigabytes of storage? Diacritic placement might be better in Office 2000, but do we really care anymore?
Caractères décomposés en langues camerounaises
Pour les langues majoritaires qui ont depuis longtemps le support de l’Unicode (français, espagnol et bien d’autres), les combinaisons courantes de diacritiques et de lettres existent déjà sous forme de caractères composés (simples) en Unicode.
En prenant l’exemple du français, toutes les combinaisons possibles de lettres et d’accents existent en Unicode comme un seul point de code (voir Fig. 1).
Encodage français
-
Fig 1: Caractères composés du français
Encodage Camerounais
Comme déterminé par la GACL, les langues camerounaises utilisent des caractères de l’alphabet latin avec des ajouts de l’Alphabet phonétique international.
Des diacritiques sont également disponibles pour les langues camerounaises afin de marquer les caractéristiques linguistiques telles que le ton, la nasalité et l’ATR.
Fig 3: Diacritiques pour les alphabets camerounais.
Le défi vient quand on essaie de combiner un caractère de l’IPA avec un diacritique, et ces combinaisons « composées » n’existent pas en Unicode. Nous sommes obligés de représenter chaque combinaison avec deux caractères ou plus (même si elle semble identique à l’utilisateur). Notez que le « i barré » (U+0268) et le « ton grave » (U+0300) se combinent, ou s’empilent, pour former un seul caractère sur la page, mais l’ordinateur les traite séparément.
-
Fig 4: Caractères décomposés à l’écran et tels qu’ils sont compris par l’ordinateur.
Ainsi, les langues minoritaires qui utilisent des combinaisons différentes sont obligées d’utiliser des caractères décomposés au moins une partie du temps. Le consortium Unicode a publié cette déclaration.
Note :
Le Consortium Unicode est intéressé à obtenir des informations sur les glyphes connus, les variantes mineures, les caractères précomposés (y compris les ligatures, les consonnes conjonctives et les caractères accentués) et d’autres « non-caractères », principalement pour le catalogage et la recherche ; cependant, ils ne sont généralement pas acceptables pour les propositions de caractère.
Justification de l’utilisation de caractères décomposés uniquement
En tant que responsable de la maintenance du clavier camerounais, l’utilisation de caractères décomposés pour les langues africaines était une décision consciente. Cette stratégie présente de nombreux avantages et ne présente aucun inconvénient.
- La manière la plus cohérente est DECOMPOSED. Il n’y a pas de caractères composés pour de nombreuses combinaisons camerounaises, telles que ə́, ʉ̀, ou ɨ̌…alors composer les quelques caractères qui existent (c.-à-d. á, é, è) rendra au mieux les données incompatibles avec certaines composées et certaines décomposées. Les diacritiques empilés (2 ou plus) existent dans de nombreuses langues camerounaises, mais la plupart n’existeront jamais comme un seul point de code.
- L’édition des langues tonales est beaucoup plus facile avec des caractères décomposés (et les Camerounais préfèrent cette méthode), car on peut revenir en arrière et changer un ton sans avoir à retaper toute la combinaison lettre/ton. Il faudrait renormaliser les données composées pour les décomposer afin de les éditer à nouveau avec le clavier.
- Tout système de vérification orthographique (qui est dans notre cour pour créer) peut être fait pour s’attendre à des caractères décomposés. Il n’y a rien de MAUVAIS en ce qui concerne l’Unicode avec la standardisation sur les caractères décomposés, et je crois que c’est la norme pour de tels langages.
- J’ai cru comprendre que le comité technique d’Unicode n’ajoute plus de versions précomposées de caractères existants à Unicode. Même s’il y avait de futures révisions Unicode qui auraient plus de combinaisons comme points de code uniques, elles prendraient beaucoup plus de place dans la police et seraient plus susceptibles d’être incomplètes.
- Le français, l’espagnol, etc. utilisent des caractères composés pour leurs accents (et le correcteur orthographique marque généralement tout le reste comme erroné), mais seulement parce que leurs combinaisons sont TRÈS peu nombreuses. Les langues romanes minoritaires et les langues Ajami… tout ce que j’ai vu jusqu’à présent qui utilise beaucoup de diacritiques, sont décomposés.
- Toutes les données camerounaises, Unicode et non Unicode sont déjà décomposées. Toutes les versions de claviers (Unicode et non Unicode) créent des caractères décomposés (même ceux qui nécessitent de taper le diacritique en premier.
- La décomposition des caractères permet de réordonner les signes diacritiques de façon programmatique, afin de garder les tons au-dessus d’une marque nasale.
- L’analyse programmatique des tons est plus facile avec des données décomposées.
- Presque aucun programme courant (Word, inDesign, Paratext, etc.) ne traite les combos composés comme équivalents à leurs équivalents décomposés. Ainsi, les recherches ne trouvent que la moitié (ou moins) de vos résultats si les données sont mélangées. Cela signifie que l’édition de texte mixte, même dans Word est une expérience TRES incohérente.
- FLEx (FieldWorks Language Explorer) décompose automatiquement les caractères pour analyse.
- Le nettoyage est plus facile dans les données décomposées.
- En français, é est un phonème différent de e, et donc la composition a un sens. Dans les langues africaines, le ton et la qualité de la voyelle peuvent être conceptuellement (et morphologiquement) séparés, il est donc plus logique de les éditer séparément.
Je suis sûr qu’il y a d’autres raisons, mais les caractères décomposés sont un fait pour les langues minoritaires et permettent aux choses de fonctionner là où elles ne le seraient pas autrement.
L’enregistrement d’un document composé peut être légèrement plus petit, mais qui compte les octets quand ils ont des gigaoctets de stockage ? Le placement diacritique pourrait être meilleur dans Office 2000, mais est-ce que cela nous concerne toujours ?
